La vérité numérique
L’illusion de la certitude dans les systèmes d’IA
Ce huitième volet de la série prolonge la maîtrise runtime développée précédemment — après avoir borné les actions (Maîtrise de l’Action), leur coût énergétique (Efficience Cognitive), il s’agit maintenant de borner de manière opposable, continue et auditable la fausseté des sorties IA. La vérité numérique n’est plus une considération éthique surajoutée : elle devient une propriété essentielle à la viabilité économique et réglementaire des déploiements d’IA autonome en Europe, qu’il s’agisse de systèmes génératifs ou de systèmes décisionnels critiques.
Une question centrale qui traverse désormais les architectures industrielles devient :
Comment transformer une sortie d'une IA en information ou décision vérifiable et traçable ?
C’est précisément cette bascule que cet article explore : faire de la vérifiabilité non pas un coût supplémentaire, mais l’infrastructure même qui autorise le passage à l’échelle sûre et rentable de l’IA autonome.
L’IA n’est pas une base de connaissances
Un LLM ou plus largement un système d’IA moderne ne "sait" pas au sens humain ; il prédit le token (ou l’action, la décision) suivant le plus probable selon sa distribution statistique apprise. Cette prédiction produit souvent un langage ou une sortie cohérent mais potentiellement faux ou incomplet. La confusion récurrente entre fluidité apparente (linguistique, logique, visuelle) et véracité factuelle reste la source principale de risque, qu’il s’agisse de génération de contenu, d’analyse prédictive, de diagnostic automatisé ou de recommandations réglementaires.
Le problème industriel de l’erreur non détectée dans l’IA
Dans les contextes critiques — juridiques, médicaux, financiers, industriels, supply chain, maintenance prédictive ou conformité réglementaire — une sortie erronée d’IA (hallucination, extrapolation hasardeuse, biais latent ou simple absence de grounding) peut entraîner :
- des décisions opérationnelles erronées aux conséquences humaines ou matérielles graves ;
- la production d’informations juridiquement non opposables ou de preuves irrecevables ;
- des dommages en chaîne (arrêts de production, rappels, litiges, atteintes à la sécurité).
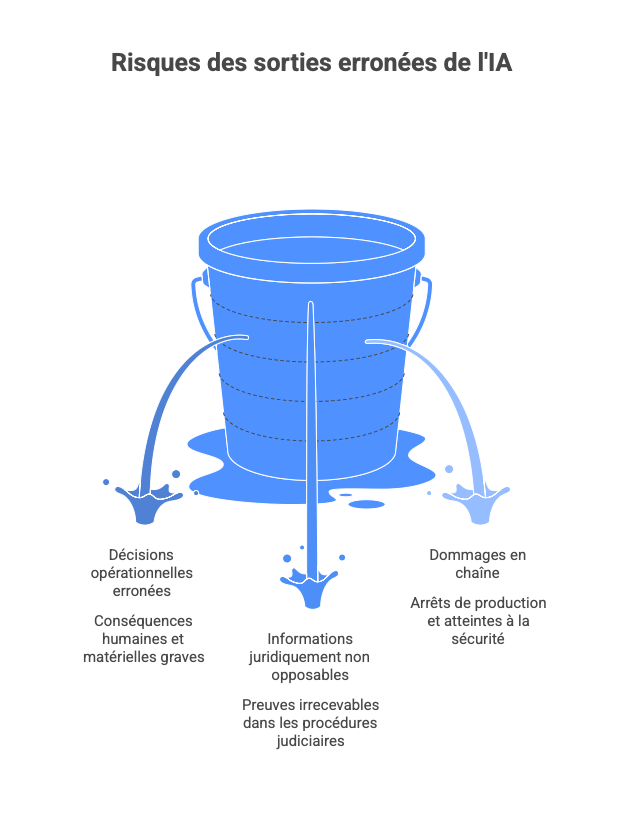
Les impacts business se trouvent sur des pertes directes (décisions basées sur du faux), indirectes (réputation, churn, perte de contrats), et des aspects réglementaires (sanctions AI Act, enquêtes CRA si défaut de sécurité exploitable).
Le coût de la vérité n'est pas halluciné
Les hallucinations et les erreurs factuelles des systèmes d’IA ont déjà généré des pertes estimées à environ 67 milliards de dollars pour les entreprises en 2024(The Hallucination Tax: Generative AI's Accuracy Problem). Avec l’entrée en vigueur pleine et effective des exigences d’accuracy, de robustesse et de cybersécurité pour les systèmes d’IA à haut risque (EU AI Act), ce coût devient un risque existentiel : amendes pouvant atteindre 35 millions d’euros ou 7 % du chiffre d’affaires mondial, surprimes d’assurance, retraits du marché, notifications obligatoires sous NIS2/DORA en cas d’incident opérationnel, et surtout une érosion accélérée de la confiance clients et partenaires.
Par exemple en 2024, le chatbot Air Canada a halluciné sur les tarifs de deuil ; Air Canada a été condamnée à rembourser le client (tribunal a rejeté l’argument « entité distincte »).
Finalement, ce risque se trouve être une opportunité : un beau différentiateur pour ceux qui le gèrent correctement.
Comprendre les erreurs et les fabrications dans les systèmes d’IA : pourquoi ils inventent ou extrapolent faussement
Le mécanisme probabiliste fondamental des modèles d’IA contemporains
Les systèmes d’IA modernes — qu’il s’agisse de LLM, de modèles multimodaux, d’agents autonomes ou de systèmes décisionnels embarqués — ne "comprennent" ni ne "savent" au sens humain. Ils modélisent des distributions de probabilité sur des séquences (tokens textuels, embeddings visuels, actions, etc.) apprises à partir de volumes massifs de données.
Chaque sortie résulte d’une prédiction du token (ou de l’action) le plus probable conditionnellement au contexte précédent, via une optimisation de type next-token prediction ou diffusion (pour les modèles génératifs visuels). Cette approche produit une cohérence statistique souvent impressionnante, mais sans ancrage ontologique ni vérification factuelle intrinsèque. C’est une illusion de compréhension que les utilisateurs et les décideurs confondent encore trop souvent avec de l’expertise.
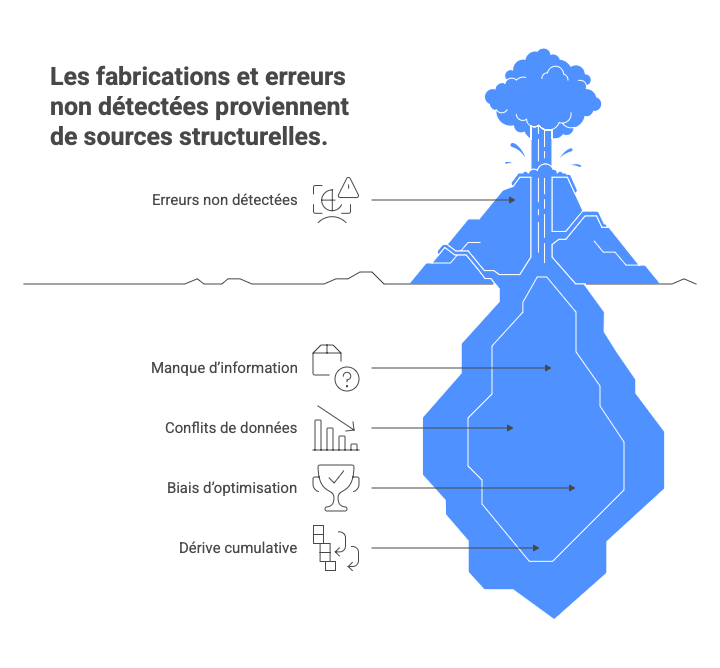
Les sources structurelles des fabrications et erreurs non détectées
-
Manque ou incomplétude d’information dans le training set ou le contexte runtime : le modèle compense par extrapolation statistique (invention plausible mais fausse).
-
Conflits et contradictions dans les données d’entraînement: les corpus massifs (Common Crawl, données web, etc.) contiennent des assertions opposées. Le modèle apprend une moyenne pondérée (sortie qui peut pencher vers l’erreur majoritaire ou la plus récente, sans arbitrage factuel).
-
Biais d’optimisation vers la complétion plutôt que l’abstention: lors du fine-tuning, les préférences humaines récompensent fortement les réponses complètes et confiantes, même incertaines.
-
Dérive cumulative dans les chaînes de raisonnement longues ou multi-étapes: les erreurs précoces se propagent.
Le risque systémique de la désinformation automatisée
Trois éléments structurent ce risque :
- Hallucination interne (erreur involontaire probabiliste) : même les modèles de pointe présentent des taux d’hallucination significatifs sur des tâches complexes.
- Manipulation volontaire : les acteurs malveillants exploitent des outils accessibles pour des campagnes de désinformation, fraudes ciblées ou attaques corporate.
- Médias synthétiques indistingueables : les deepfakes réactifs en temps réel et le contenu AI slop saturent les canaux, générant un liar’s dividend : les preuves authentiques peuvent être discréditées comme synthétiques, érodant la confiance globale. Aujourd'hui un être humain se retrouve démuni face aux deepfake qui sont d'un réalisme époustouflant.
L’érosion de la preuve numérique
- Une image n’est plus une preuve irréfutable (deepfakes visuels sophistiqués, absence de provenance fiable).
- Un texte n’est plus une expertise incontestable (hallucinations factuelles/juridiques, fabrications plausibles).
- Une vidéo n’est plus un témoignage fiable (clonage facial + vocal en temps réel, indistinguishable threshold franchi).
- Une décision IA n’est plus opposable sans traçabilité et preuve de robustesse (exigences AI Act Art. 15 accuracy/robustness).
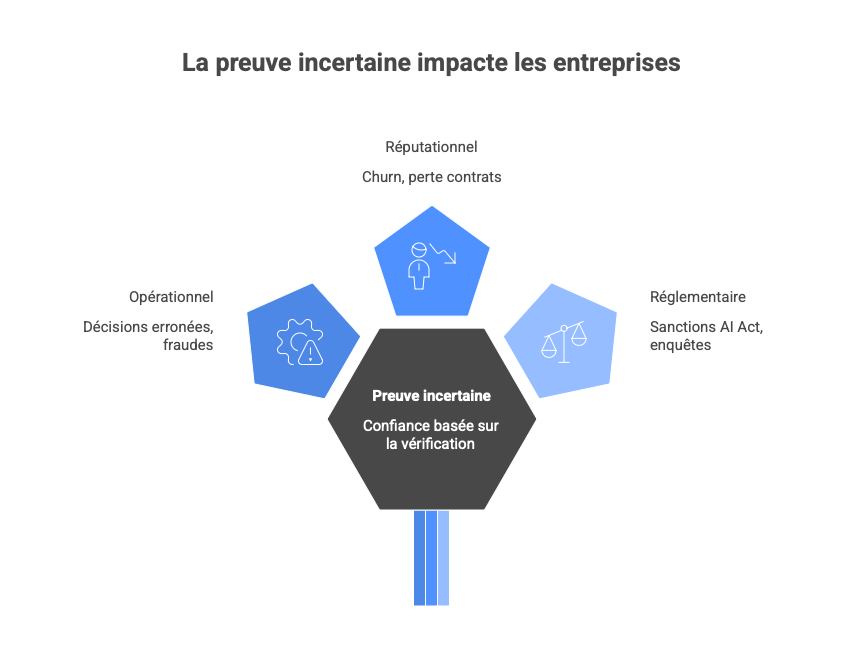
Aujourd'hui, la preuve devient incertaine, la confiance ne repose plus sur le contenu apparent mais sur l’infrastructure de vérification (provenance C2PA, grounding sur KG, audits multi-agents, confidence scoring bloquant). Les impacts touchent trois niveaux :
- Opérationnel : Décisions erronées, fraudes (voice cloning CEO pour transferts), arrêts production.
- Réputationnel : Churn, perte contrats, érosion marque (secteurs finance, santé, médias).
- Réglementaire : Sanctions AI Act, enquêtes, notifications incidents, surprimes assurance.
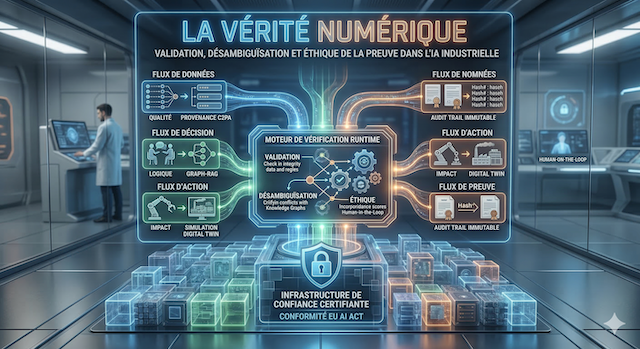
Les flux de vérifications
La vérification devrait intervenir, en temps réel et de manière bloquante si nécessaire. Il convient toutefois de noter que les solutions techniques proposées ne sont pas parfaites : elles permettent de réduire les risques d’erreurs et d’hallucinations, mais ne les éliminent jamais complètement. Chaque approche introduit ses propres limitations, telles que des surcoûts computationnels, une latence accrue ou une dépendance à la qualité des données et des règles sous-jacentes. Cette approche par flux (données, décision, action, preuve) s’aligne sur une littérature émergente sur les pipelines d’IA vérifiables de bout en bout, qui cherche à relier, par des preuves cryptographiques ou des garanties formelles, chaque étape du cycle de vie : qualité et provenance des données, entraînement, inférence et même unlearning. Ces travaux montrent que la vérifiabilité ne peut plus être traitée comme un simple contrôle a posteriori, mais comme une propriété architecturale à concevoir dès la pipeline (E2E pipeline).
Flux de données
C’est le premier verrou : toute erreur ici se propage et alimente les hallucinations ou les biais latents décrits précédemment.
- Pipelines automatisés de data quality gates (validation de complétude, fraîcheur, cohérence statistique)
- Traçabilité de provenance native (extension du standard C2PA aux datasets ou utilisation de registres blockchain/Immutable Ledger)
- Détection et mitigation des biais via outils neurosymboliques intégrés au preprocessing et au RAG hybride (vectoriel + Knowledge Graph).
Limitations : Ces mécanismes améliorent la qualité des entrées mais restent imparfaits. Les data quality gates automatisées peuvent passer à côté de biais contextuels subtils ou de données empoisonnées sophistiquées. La traçabilité via C2PA (qui ne prouve que la provenance) ou ledgers n’empêche pas les problèmes en amont du pipeline et peut complexifier les architectures existantes. La détection des biais neurosymbolique dépend fortement de la pertinence des règles définies par l’humain.
Flux de décision
Ici, la vérification porte sur la cohérence logique et le respect des règles métier — bien au-delà des simples LLM. Elle concerne aussi les systèmes de raisonnement en chaîne, les agents autonomes et les modèles de scoring embarqués.
Points techniques :
- Par exemple, Graph-RAG et requêtes KG déterministes pour ancrer les inférences probabilistes
- Constrained decoding + moteurs de règles neurosymboliques (type Llama Guard + custom constraint solvers)
- Débat multi-agents (« Juge-Avocat-Expert ») avant toute sortie finale, avec calcul runtime du confidence score factuel. Cette logique s’inscrit dans un mouvement plus large où l’on combine RAG, Graph‑RAG et multi‑agent debate pour améliorer la factualité des LLM. Des travaux récents sur Graph‑RAG multi‑agents montrent qu’une exploration adaptative de graphes de connaissance, orchestrée par plusieurs agents spécialisés, peut améliorer significativement la précision factuelle sur des tâches complexes. D’autres architectures RAG intègrent déjà des modules explicites de retrieval, debate and verification pour limiter les hallucinations et contrôler les sorties par rapport à une base de connaissances structurée (Graph Counselor)
Limitations : Le débat multi-agents et le Graph-RAG augmentent la complexité et la latence du système, il n'est pas fiable à 100% (un LLM qui juge un autre LLM). Plusieurs modèles peuvent partager des biais communs, limitant l’efficacité du consensus. Le score de confiance, bien qu’utile, reste une métrique probabiliste et ne constitue pas une preuve de vérité absolue (d'autant plus quand il émit par des techniques de type LLM-as-a-Judge). Dans les chaînes de raisonnement longues, les erreurs peuvent encore se propager malgré ces garde-fous.
Flux d’action
La vérification doit ici évaluer l’impact réel sur le monde physique ou opérationnel et activer la supervision humaine quand le risque dépasse un seuil calibré.
Points techniques :
- Simulation en temps réel via digital twin ou sandbox d’impact avant exécution
- Runtime governance avec blocage automatique
- Boucle Human-in-the-Loop (HITL) ou Human-on-the-Loop (HOTL) avec escalade contextuelle et journalisation immutable. Ces mécanismes de simulation, de runtime governance et de blocage s’inscrivent dans les travaux émergents sur la gouvernance des pipelines d’IA, qui visent à contrôler finement ce que peuvent faire les agents (actions, accès, modifications de systèmes) et à lier chaque action à des politiques de conformité vérifiables. Des travaux plus cryptographiques explorent même l’idée de pipelines d’IA décentralisés où chaque étape (y compris l’action) est attestée par des preuves de type zero‑knowledge, ouvrant la voie à des chaînes de décision auditable sans exposition complète des données ou des modèles (pipeline goernance).
Limitations : Les simulations via digital twin sont coûteuses et ne reproduisent jamais parfaitement la réalité complexe. Les mécanismes de blocage automatique peuvent générer trop de faux positifs, impactant l’utilité opérationnelle. Les boucles HITL/HOTL dépendent de la disponibilité et de la vigilance humaine, qui n’est pas infaillible.
Flux de preuve
Dernier maillon : tout ce qui précède doit être rendu opposable en justice, auditable et traçable pour les autorités, les assureurs et les tribunaux.
Points techniques :
- Génération automatique de certificats de provenance (C2PA multilayered + watermarking imperceptible)
- Audit trails cryptographiquement signés et stockés dans un registre immutable
- Rapport de vérité runtime incluant le chemin de raisonnement, les sources KG consultées, le confidence score et les interventions humaines.
Les cadres de verifiable AI pipelines insistent précisément sur ce dernier maillon : relier les preuves produites à chaque étape (données, entraînement, inférence, unlearning) pour offrir un récit complet et vérifiable, compatible avec les exigences réglementaires type AI Act. Dans ce contexte, la combinaison de C2PA, de watermarking et de registres immuables s’inscrit dans un mouvement plus large de standardisation de l’authentification de contenu synthétique et de la traçabilité des décisions algorithmiques.(AI Content Authentication)
Limitations : La mise en œuvre de C2PA et des registres immuables ajoute une surcharge technique et de stockage importante et n'est pas parfaite. Les watermarking peuvent être contournés dans certains cas ou altérés par des traitements ultérieurs. L’auditabilité complète reste difficile à maintenir à grande échelle sur des systèmes distribués complexes.
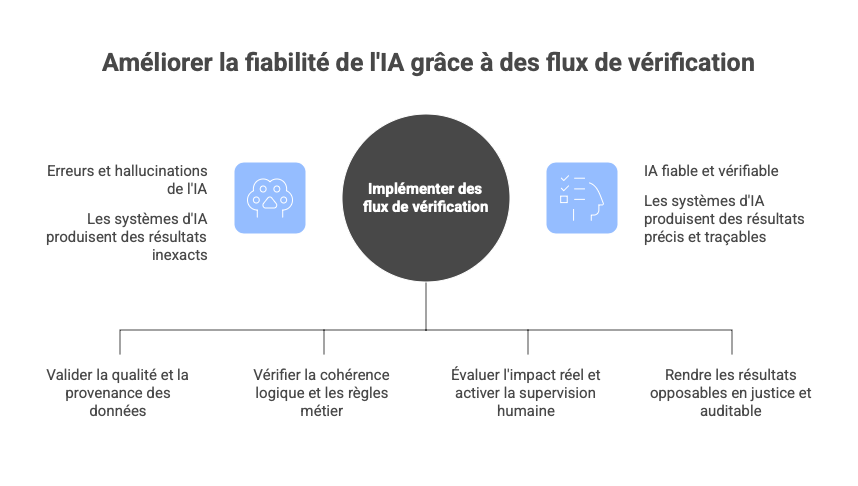
En intégrant ces quatre flux dans une gouvernance runtime unifiée, l’IA gagne en fiabilité relative. La vérification n’élimine pas tous les risques mais constitue un élément important pour améliorer la maîtrise des systèmes.
L’éthique de la vérité algorithmique
Dans la continuité directe de la validation comme infrastructure système (RAG hybride, Knowledge Graphs, multi-agent debate) et des quatre flux critiques (données, décision, action, preuve), l’éthique de la vérité algorithmique ne se limite plus à l’IA générative. Elle devient une contrainte runtime obligatoire pour tous les systèmes d’IA industriels : agents autonomes en chaîne de raisonnement longue, modèles embarqués de maintenance prédictive, systèmes décisionnels high-risk (diagnostic médical, scoring financier, optimisation supply chain) ou contrôle-commande IoT critique. Cette éthique transforme la vérifiabilité opposable en un levier de responsabilité sociétale, de réduction de risque et de conformité pleine à l’EU AI Act, faisant passer l’IA d’un outil probabiliste à une infrastructure vérifiable et traçable.
Le devoir de transparence
Les systèmes IA, qu’ils génèrent du texte, des décisions opérationnelles ou des actions physiques, doivent indiquer de manière systématique, machine-readable et auditable le degré de certitude, provenance de l’information, les limites du modèle
L’acceptation de l’incertitude
Un système responsable devrait pouvoir dire, de manière calibrée et bloquante :
"Je ne sais pas. Précisez votre question ou fournissez des données supplémentaires."
ou
"Cette inférence dépasse mon seuil de confiance calibrée; recommandation d’escalade humaine ou abstention."
La capacité à refuser une réponse ou à activer une boucle Human-in-the-Loop (HITL) ou Human-on-the-Loop (HOTL) devient un critère de qualité mesurable, intégré aux métriques d’accuracy et de robustesse exigées par l’AI Act.
La difficulté majeur de l'HITL ou l'HOTL étant que sur des millions de transactions il n'est pas concevable de demander à un être humain de valider tout le temps. Dès lors des systèmes de classification ou de seuils doivent être mise en place pour traiter "manuellement" les éléments les plus critiques et accepter que des erreurs vont apparaître.
D'autres l'humain a un biais de confirmation : "si l'IA dit ça doit être vrai". Ici il est essentielle que l'IA force l'utilisateur à réflichir, par exemple en posant des questions sur son raisonnement.
Conclusion — La vérité comme infrastructure
L’hallucination n’est pas un bug.
C’est une propriété naturelle des modèles probabilistes.
Comment construire des systèmes capables de détecter, corriger et prouver la vérité ?
La précision brute est vaine sans la "garantie" de véracité. Un modèle qui produit 99 % de cohérence linguistique ou décisionnelle mais sans ancrage factuel (Knowledge Graph déterministe, Graph-RAG hybride, débat multi-agents "Juge-Avocat-Expert") reste une boîte noire coûteuse. Même si cet ancrage factuel est une rustine, elle a le mérite de limiter les erreurs et d'imposer de bonnes pratiques.
Lego II - RegOS - Sac 8
Les opinions exprimées dans cet article sont strictement personnelles et ne reflètent pas nécessairement celles de mon employeur. Les contenus sont fournis à titre informatif et ne constituent pas un conseil juridique. Cet article explore des concepts architecturaux émergents et analyse des tendances de marché. RegOS est ici une proposition conceptuelle personnelle et non propriétaire — un cadre d'ingénierie systémique que j'explore pour contribuer au débat public sur la conformité IA industrialisée en Europe.